Kể từ những ngày đầu của công nghệ máy tính cho đến nay, sự phát triển của dữ liệu ngày một tăng - điều này có tác động trực tiếp đến nhu cầu về công nghệ lưu trữ, xử lý và phân tích dữ liệu. Trong một thập kỷ trở lại đây, có một xu hướng dịch chuyển từ cơ sở dữ liệu SQL sang NoSQL, và MongoDB đang chiếm ưu thế về độ phổ biến, như một công cụ lưu trữ dữ liệu mới trên thế giới.
Và cũng vì lý do đó mà các vấn đề về thiết kế bên trong MongoDB trở nên đáng quan tâm hơn. Hầu hết mọi người đều nghĩ rằng design pattern chỉ áp dụng cho phía backend, nhưng sự thực không phải vậy. Các lựa chọn thiết kế không hợp lý sẽ ảnh hưởng nghiêm trọng đến khả năng mở rộng và hiệu suất của giải pháp.
Vì vậy hôm nay, tôi sẽ giới thiệu một vài design pattern MongoDB thực tế mà các dev full stack nên biết (dù là sử dụng MERN Stack hay MEAN Stack).
- Polymorphic Schema
- Aggregate Data Model
- Mimicking Transactional Behavior
Polymorphic Schema
Một câu hỏi thường xuyên với những newbie mới tiếp cận MongoDB là “Làm thế nào để cấu trúc dữ liệu trong MongoDB cho ứng dụng của tôi”. Câu trả lời thẳng thắn là, tuỳ thuộc. Ứng dụng của bạn có cần đọc nhiều hơn ghi? Dữ liệu trong ứng dụng của bạn liên kết như thế nào khi được gọi? Vấn đề hiệu suất như thế nào? Các document lớn cỡ bao nhiêu? Ứng dụng của bạn sẽ phát triển như thế nào?
Tất cả câu hỏi trên đều hướng tới một vấn đề chung là thiết kế lược đồ cơ sở dữ liệu trong MongoDB. Hầu hết các vấn đề gặp phải đều liên quan đến việc thiết kế lược đồ dữ liệu kém. Vì đa số đều nghĩ MongoDB là schemaless. Nhưng thực tế không phải vậy, MongoDB vẫn có schema chỉ là nó động thôi.
Ở các RDBSM, dữ liệu được lưu theo cấu trúc cố định, chúng được thêm vào dạng hàng, và có thuộc tính là các cột. Điều này đồng nghĩa tất cả các dữ liệu được thêm vào trong một bảng sẽ có thuộc tính như nhau.
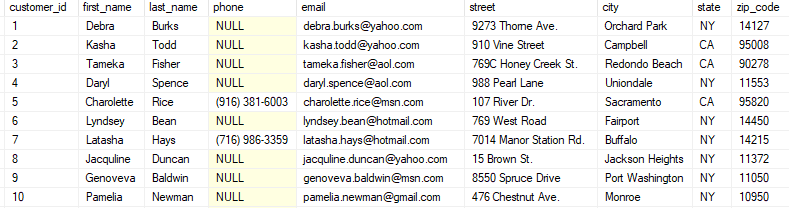
Ví dụ như trên, tất cả các dữ liệu được thêm sẽ có thuộc tính customer_id, first_name, last_name, phone, email ,… những thuộc tính cập nhật sẽ có giá trị NULL, nhưng chúng vẫn có thuộc tính đó. Đều này là tốt cho các dữ liệu có cấu trúc, nhưng sẽ không tốt cho các dữ liệu phi cấu trúc.
Trong MongoDB, dữ liệu được lưu dưới dạng document trong một collection, chúng có điểm tương đồng về cấu trúc nhưng không giống nhau hoàn toàn, được gọi là Polymorphic Schema.
Ví dụ trang mạng xã hội có các bài post sau:
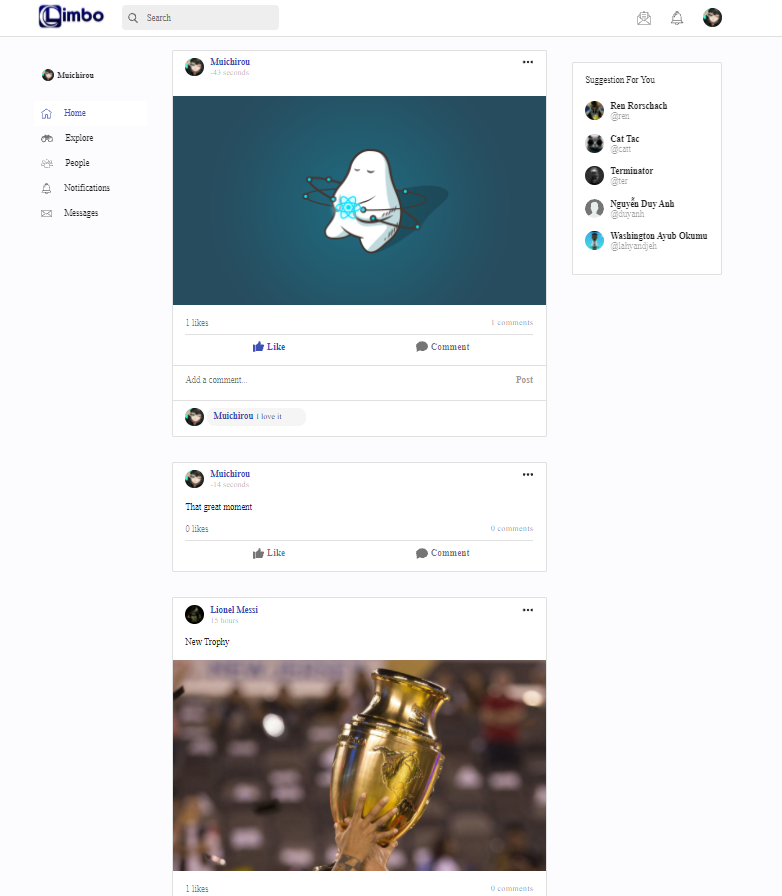
Ta có thể thấy bài post đầu tiên, chỉ có ảnh không có tiêu để, post thứ hai có tiêu đề không có ảnh và post thứ ba có cả hai.Mà ta vẫn có thể lưu trữ nó dễ dàng trong MongoDB, vì các document cùng nằm trong collection có thể có các thuộc tính khác nhau.
Một ví dụ khác, như ta cần một ứng dụng theo dõi các vận động viên trong kỳ Olimpic. Ta cần truy cập tất cả các vận động viên, nhưng mà các vận động viên các môn thể thao khác nhau sẽ có thuộc tính trong cơ sở dữ liệu khác nhau. Và lúc này Polymorphic Schema lại tiếp tục toả sáng.
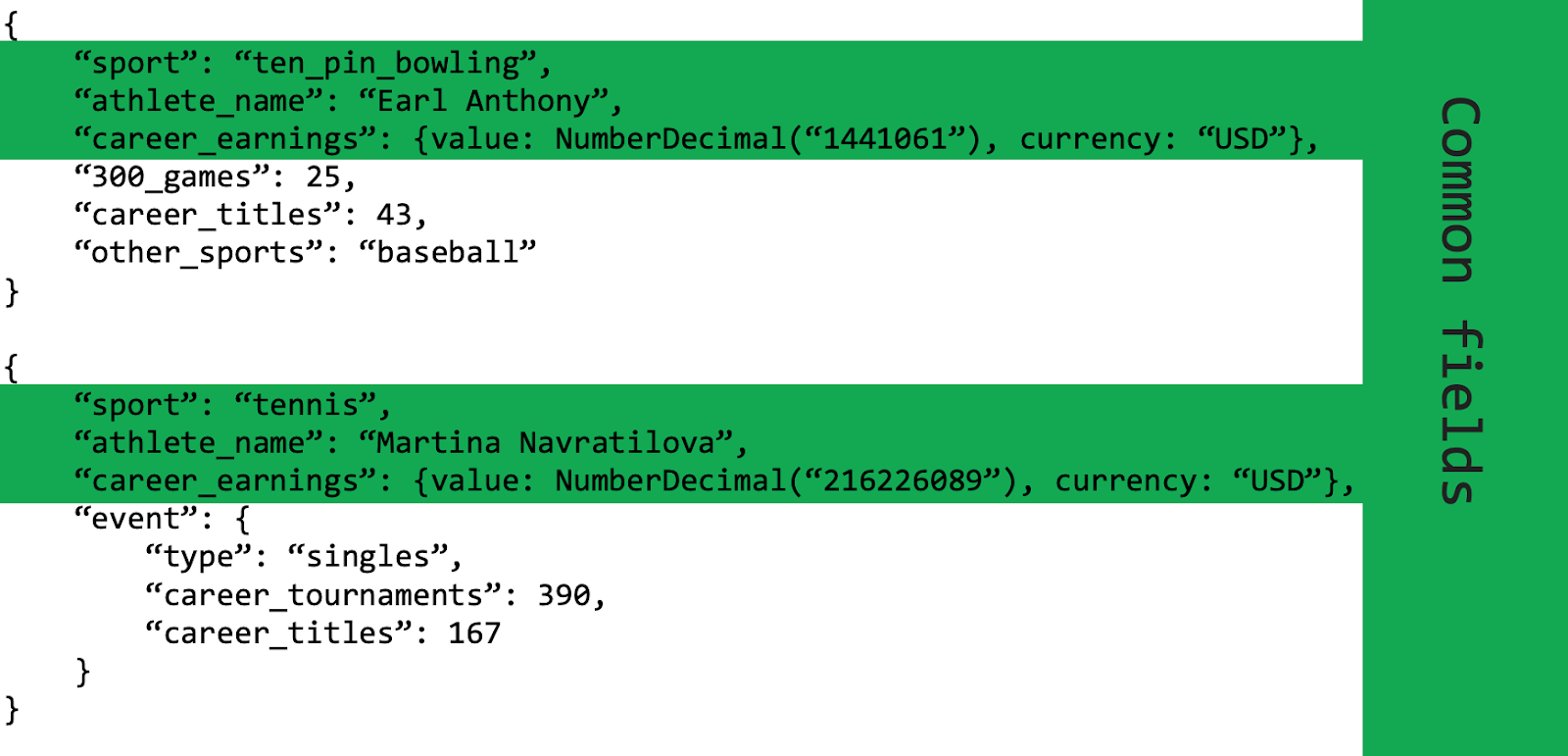
Các vận động viên sẽ có những thuộc tính tương đồng nhau, nhưng với các thuộc tính khác biệt ta cũng có thể dễ dàng điều chỉnh nó. Ở đây ta có thể gọi truy vấn Athlete.find() sẽ gọi tất cả các vận động viên trong collection. Từ ví dụ trên, khi triển khai Polymorphic Schema, ta sẽ xem xét các trường cụ thể trong document hay sub-document để theo dõi sự khác biệt.
Polymorphic Schema sẽ được dùng cho các document có nhiều điểm tương đồng và một ít khác biệt. Nó có thể được sử dụng cho các:
- Ứng dụng xem một lần
- Quản lý nội dung
- Ứng dụng di động
- Danh mục sản phẩm