Với những ai đã sử dụng SQL họ thường than phiền rằng MongoDB quá thiếu liên kết, các document rời rạc và khó truy vấn khi cần thống kê dữ liệu. Họ muốn những câu lệnh gom nhóm, lọc, tương tự như GROUP BY hay JOIN trong SQL. Và các em thích thì chiều, MongoDB đã giới thiệu một framework là Aggregation để bạn làm các công việc, gom nhóm, lọc, giới hạn, … nhằm giúp bạn có thể thống kê dữ liệu mà mình mong muốn một cách dễ dàng.
Ở bài viết này mình sẽ dùng một mô hình dữ liệu thương mại điện tử, để mọi người có cái nhìn chi tiết về aggregation, các toán tử của nó và các tuỳ chọn cho từng toán tử.
Overview
Lệnh gọi framework aggregation có thể xác định theo pipeline sau:

Trong pipeline, mỗi output của phần này là input của phần tiếp theo. Mỗi bước thực hiện một thao tác giúp chuyển document đầu vào thành document đầu ra theo yêu cầu.
Aggregation pipeline có các toán tử sau:
- $project : Chỉ định các trường sẽ xuất hiện trong document output.
- $match : Chọn các document cần xử lý, tương tự với
find(). - $limt : Giới hạn số lượng document được chuyển sang bước tiếp theo.
- $skip : Bỏ qua một lượng document nhất định.
- $unwind : Thực hiện thao tác mở rộng trên một mảng , tạo một document output cho mỗi giá trị trong mảng đó.
- $group : Gom nhóm document theo yêu cầu cụ thể.
- $sort : Sắp xếp document theo thuộc tính.
- out: Ghi kết quả sau khi thực hiện trên pipeline vào một collection. (new v2.6)
Ví dụ ta có aggregation pipeline cho match, group và sort:
db.products.aggregate([ {$match: ...}, {$group: ...}, {$sort: ...} ] )
Lúc này pipeline có thể biểu diễn:

Như những gì trong hình mô tả:
- Toàn bộ collection
productsẽ được chuyển vào toán từ $match, sau đó chỉ những document nào ứng với $match, được cho ra output. - Sau đó các document được truyền cho toán tử $group, tại đây nó sẽ gom nhóm các document theo các key cụ thể để cung cấp thông tin mới, như tổng hay trung bình cộng.
- Cuối cùng, nó được truyền vào $sort, nơi sẽ sắp xếp các document theo một thuộc tính nào đó và cho ra kết quả cuối cùng.
Dành cho những ai đã quen với SQL, thì ta có một bảng các câu lệnh SQL tương ứng với các toán tử aggregation như sau:
| SQL | Aggregation operator |
|---|---|
| SELECT | $project |
| $group functions: $sum, $min, $avg, etc. | |
| FROM | db.collectionName.aggregate(…) |
| JOIN | $unwind |
| WHERE | $match |
| GROUP BY | $group |
| HAVING | $match |
$project
$project được dùng để chỉ định các field sẽ xuất hiện trong output document. Đó có thể là các field đã tồn tại trong input document, hoặc cũng có thể là các field được tính toán mới.
Cú pháp:
{ $project: { <specification(s)> } }
Trong đó, specification có thể có các dạng sau:
_id <0 or false>: field _id sẽ không xuất hiện trong output document (mặc định _id luôn xuất hiện trong output document).<field X>: <1 or true>: field X sẽ xuất hiện trong output document.<field X>: <expression>: field X sẽ được tính toán dựa trên một expression nào đó.
Ví dụ:

$group
$group được dùng để gom nhóm các document đầu vào theo expression. Mỗi nhóm tương ứng với một document output.
Cú pháp:
{
$group:
{
_id: <expression>, // Group By Expression
<field1>: { <accumulator1> : <expression1> },
...
}
}
Nếu _id bằng null, thì sẽ truy vấn tất cả các document đầu vào.
Ta có bảng các accumulator được dùng trong $group như sau:
| Accumulator | Description |
|---|---|
| $addToSet | Tạo một mảng các giá trị duy nhất cho nhóm. |
| $first | Giá trị đầu tiên trong một nhóm. Chỉ có ý nghĩa nếu đứng trước $sort. |
| $last | Giá trị cuối cùng trong một nhóm. Chỉ có ý nghĩa nếu đứng trước $ sort. |
| $max | Giá trị tối đa của trường cho một nhóm. |
| $min | Giá trị nhỏ nhất của trường cho một nhóm. |
| $avg | Giá trị trung bình cho một trường. |
| $push | Trả về một mảng gồm tất cả các giá trị cho nhóm. Không loại bỏ các giá trị trùng . |
| $sum | Tổng của tất cả các giá trị trong một nhóm. |
Ví dụ, tổng kết doanh số bán hàng theo tháng và năm.
> db.orders.aggregate([
... {$match: {purchase_data: {$gte: new Date(2010, 0, 1)}}},
... {$group: {
... _id: {year : {$year :'$purchase_data'},
... month: {$month :'$purchase_data'}},
... count: {$sum:1},
... total: {$sum:'$sub_total'}}},
... {$sort: {_id:-1}}
... ]);
Kết quả:
{ "_id" : { "year" : 2014, "month" : 11 },
"count" : 1, "total" : 4897 }
{ "_id" : { "year" : 2014, "month" : 8 },
"count" : 2, "total" : 11093 }
{ "_id" : { "year" : 2014, "month" : 4 },
"count" : 1, "total" : 4897 }
$match, $sort, $skip, $limit
Ở đây nói về cả 4 toán tử này, vì chúng có phần tương đồng với các truy vấn MongoDB thông thường. Ta sẽ thử so sánh như sau.
- Đây là các truy vấn thông thường:
page_number = 1
product = db.products.findOne({'slug': 'wheelbarrow-9092'})
reviews = db.reviews.find({'product_id': product['_id']}).
skip((page_number - 1) * 12).
limit(12).
sort({'helpful_votes': -1})
- Còn đây là khi ta dùng aggregation:
reviews2 = db.reviews.aggregate([
{$match: {'product_id': product['_id']}},
{$skip : (page_number - 1) * 12},
{$limit: 12},
{$sort: {'helpful_votes': -1}}
]).toArray();
Ta có thể thấy, chức năng và tham số của cả hai là như nhau. Sự khác biệt duy nhất có lẽ là hàm find() ta có thể truy vấn bằng biểu thức javascript. Điều không thể làm với $match.
$unwind
unwind được dùng để phân tách giá trị của một mảng field trong các document đầu vào. Nếu như mảng field của một document có N phần tử thì trong output sẽ có N document.
Ví dụ, nếu thông thường ta truy vấn trường category_ids của product như sau:
> db.products.findOne({},{category_ids:1})
Ta sẽ có kết quả là một document chứac field là category_ids:
{
"_id" : ObjectId("4c4b1476238d3b4dd5003981"),
"category_ids" : [
ObjectId("6a5b1476238d3b4dd5000048"),
ObjectId("6a5b1476238d3b4dd5000049")
]
}
Với $unwind, khi ta thực hiện lệnh:
> db.products.aggregate([
... {$project : {category_ids:1}},
... {$unwind : '$category_ids'},
... {$limit : 2}
... ]);
Ta sẽ có các document riêng biệt với từng category_ids:
{ "_id" : ObjectId("4c4b1476238d3b4dd5003981"),
"category_ids" : ObjectId("6a5b1476238d3b4dd5000048") }
{ "_id" : ObjectId("4c4b1476238d3b4dd5003981"),
"category_ids" : ObjectId("6a5b1476238d3b4dd5000049") }
Ứng dụng
Như đã hứa, bây giờ ta sẽ dùng các toán tử aggregation với mô hình dữ liệu thương mại điện tử. Trước tiên, ta có mô hình dữ liệu cho trang thương mại điện tử như sau:

Trong mô hình dữ liệu trên, ta có 5 collection là: Users, Products, Categories, Reviews và Orders. Mỗi collection sẽ có cấu trúc document, chỉ ra các trường riêng biệt vd như products sẽ có price_history, category_ids và tags.
Products, categories và reviews
Trước tiên ta sẽ thử sử dụng aggregation để tổng hợp thông tin tóm tắt về product. Thông thường để lấy tổng số review cho tất cả product chúng ta sẽ làm như sau:
product = db.products.findOne({'slug': 'wheelbarrow-9092'})
reviews_count = db.reviews.count({'product_id': product['_id']})
Bây giờ ta sẽ dùng aggregation để làm cả hai việc trên cùng một lúc:

Lúc này dữ liệu mà ta nhận được như sau:

Trong ví dụ trên, ta có nhiều document review, nhưng với toán tử $group các document này sẽ được gộp lại. Như vậy với đoạn lệnh trên, các document review có product_id giống nhau, sẽ được gom lại. Và sẽ tính tổng tất cả cả document có product_id giống nhau.
Bây giờ ta muốn lấy các document review của một product cụ thể như sau:

Đoạn lệnh trên sẽ trả về một product mà bạn mong muốn, và gán product đó cho biến ratingSummary. Hãy nhớ là kết quả từ aggregation pipeline là một con trỏ, cho phép ta xử lý kết quả ở mọi kích thước. Để truy xuất document từ con trỏ, ta sử dụng hàm next() để trả về document đầu tiên của con trỏ. Kết quả cho đoạn lệnh trên:
{ "_id" : ObjectId("4c4b1476238d3b4dd5003981"), "count" : 3 }
Ở các phiên bản trước MongoDB v2.6, kết quả từ aggregation pipeline là một document duy nhất, với kích thước tối đa 16MB. Từ MongoDB v2.6 trở đi, ta có thể xử lý bất kỳ kích thước nào bằng con trỏ. Tuy nhiên để tránh ảnh hưởng đến các chương trình hiện có, mặc định các document vẫn giới hạn 16MB. Song bạn cũng có thể ghi đè lên mặc định này.
Bây giờ ta sẽ chuyển sang tính reviews trung bình của một product.

Với đoạn lệnh trên, ta có được kết quả sau:
{
"_id" : ObjectId("4c4b1476238d3b4dd5003981"),
"average" : 4.333333333333333,
"count" : 3
}
Đếm review theo rating
Công việc tiếp theo mà các trang thương mại điện tử có là đếm review theo rating. Như trong hình minh hoạ sau:
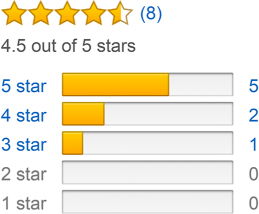
Như trong hình trên, có 8 lượt rating: 5 người cho 5 sao, 2 người cho 4 sao và 1 người cho 3 sao.
Với aggregation, ta có thể làm điều này chỉ với một câu lệnh duy nhất. Mà cụ thể ở trường hợp này ta sẽ dùng lệnh $match để tìm product cụ thể, sử dụng $group để gom các review có rating giống nhau. Và cộng chúng lại:

Kết quả cho lệnh gọi aggregate này vẫn là một con trỏ, ta đã chuyển nó thành mảng và gán cho biến countsByRating.
Trong SQL nó sẽ tương ứng với câu truy vấn
SELECT RATING, COUNT(*) AS COUNT
FROM REVIEWS
WHERE PRODUCT_ID = '4c4b1476238d3b4dd5003981'
GROUP BY RATING
Và tất nhiên là cả hai đều sẽ đạt được kết quả như sau:
[ { "_id" : 5, "count" : 5 },
{ "_id" : 4, "count" : 2 },
{ "_id" : 3, "count" : 1 } ]
Join Collection
Bây giờ, ta muốn đếm số product theo từng category. Nhớ lại rằng, mỗi product chỉ có một category, thế nên lệnh aggregation như sau:
db.products.aggregate([
{$group : { _id:'$main_cat_id',
count:{$sum:1}}}
]);
Và ta sẽ có kết quả là:
{ "_id" : ObjectId("6a5b1476238d3b4dd5000048"), "count" : 2 }
Chỉ với kết quả này thì không hữu ích lắm, vì ta không biết được category nào là ObjectId("6a5b1476238d3b4dd5000048"). Một trong những hạn chế của MongoDB là nó không hỗ trợ join hai collection.